in General on Rust, Markov, Pattern, Procedural, Rpg, FantasyLast modified at:
Role-playing and adventure games often require a considerably high number of names to describe characters, locations, items, events, abilities, etc.
Humans are very awful generators of randomness, especially upon request. Writers and designers can come up with a handful of well devised names for important identifiers, but having a human generate 100 character names will likely result in many duplicates or boring derivatives.
There are a few approaches to this problem:
Pattern substitution of a data set with explicit rule-based probability.
Using Markov chains to synthesize new results from a data set.
Training a neural network to synthesize new results from a data set.
in Graphics on Vulkan, Ray tracing, Hlsl, RustLast modified at:
At GDC 2018, Nvidia and Microsoft announced DirectX ray tracing (DXR), along with some cool demos like our PICA PICA work at EA SEED.
Our ray tracing support was implemented in the DirectX 12 backend of our high-performance research engine Halcyon, without equivalent functionality in our other low level backends. Since that GDC, Nvidia has released their own vendor-specific Vulkan extension for ray tracing. Here are some relevant links:
This post is not a tutorial for using the VK_NV_ray_tracing extension, there are a number of good tutorials already available such as this one.
Instead, I wanted to show how to use HLSL as the only source language, and target both DXR and VK_NV_ray_tracing, made possible by a recent pull request by Nvidia to Microsoft’s DirectX shader compiler (DXC).
in Cloud on Kubernetes, Endpoints, Grpc, Stackdriver, Services
After a lot of fighting and tricky debugging, I managed to get Google Cloud Endpoints working for some rust gRPC services. In order for others to benefit from it, I wanted to document some parts of the process here.
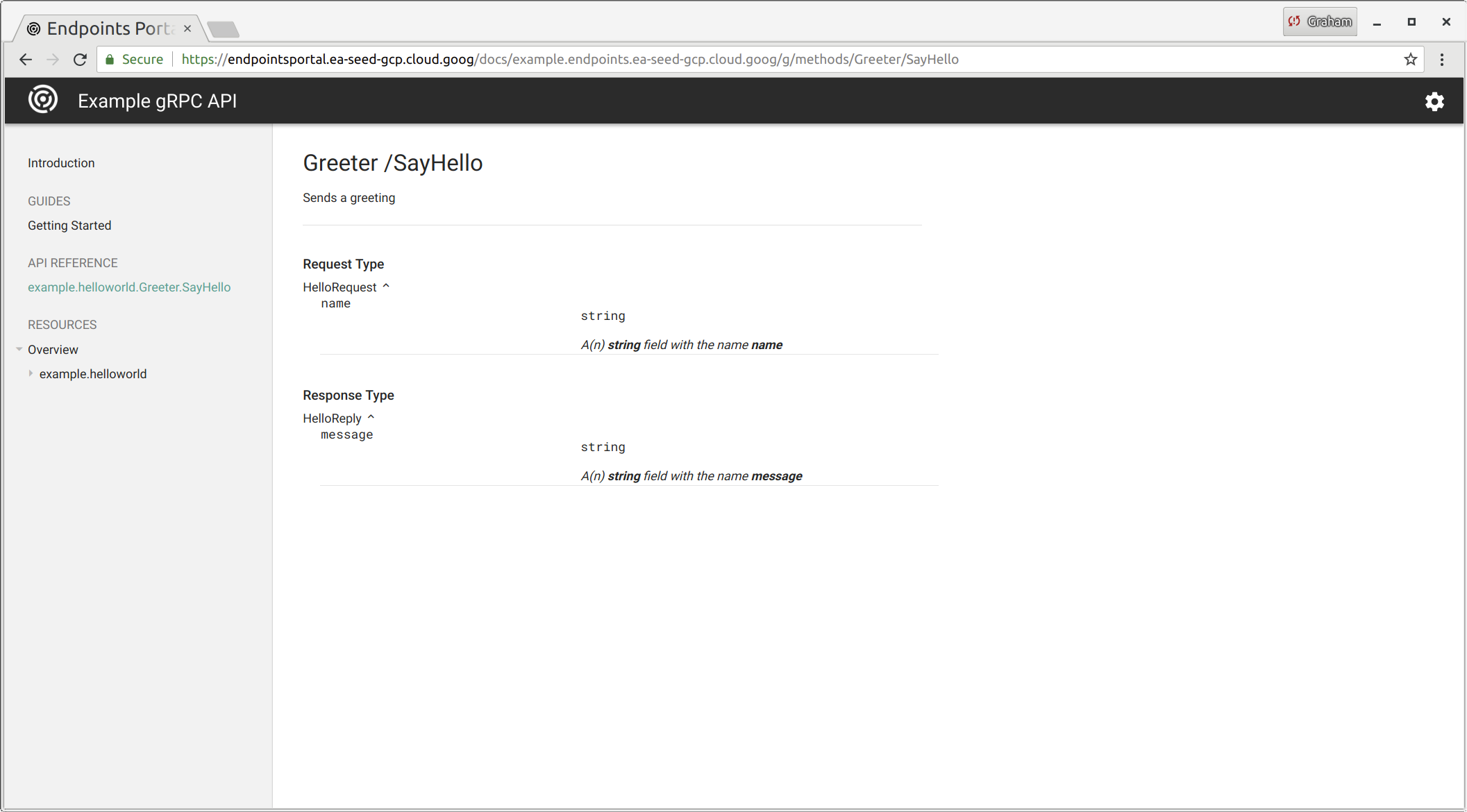
syntax="proto3";packageexample.helloworld;// The greeting service definition.serviceGreeter{// Sends a greetingrpcSayHello(HelloRequest)returns(HelloReply){}}// The request message containing the user's name.messageHelloRequest{stringname=1;}// The response message containing the greetingsmessageHelloReply{stringmessage=1;}
Google Cloud Endpoints will reflect on your service’s API using a protobuf descriptor file, which you can generate using the protobuf compiler protoc:
The descriptor set name doesn’t actually matter; I’ll use example.pb in this example.
Endpoint Configuration
The endpoints are configured with a custom yaml file (app_config.yaml). This file specifies the description of the service (i.e. Example gRPC API), the service name where the endpoint is deployed (i.e. example.endpoints.ea-seed-gcp.cloud.goog), the authentication/security rules (ignored in this example), and the protobuf service path.
For the service path (i.e. example.helloworld.Greeter), this needs to exactly match your protobuf file. Take the package name (i.e. example.helloworld) and append the service name (i.e. Greeter).
# The configuration schema is defined by service.proto file# https://github.com/googleapis/googleapis/blob/master/google/api/service.prototype:google.api.Serviceconfig_version:3# Name of the service configurationname:example.endpoints.ea-seed-gcp.cloud.goog# API title to appear in the user interface (Google Cloud Console)title:Example gRPC APIapis:-name:example.helloworld.Greeter# API usage restrictionsusage:rules:# Allow unregistered calls for all methods.-selector:"*"allow_unregistered_calls:true
With a valid app_config.yaml and example.pb generated, the endpoint can be deployed to GCP:
% Operation finished successfully. The following command can describe the Operation details:
% gcloud endpoints operations describe operations/serviceConfigs.example.endpoints.ea-seed-gcp.cloud.goog:21066c83-6899-4870-88a0-78da0c630d88
% Operation finished successfully. The following command can describe the Operation details:
% gcloud endpoints operations describe operations/rollouts.example.endpoints.ea-seed-gcp.cloud.goog:1d62ceec-05f8-46c9-8184-595eff79391e
% Enabling service example.endpoints.ea-seed-gcp.cloud.goog on project ea-seed-gcp...
% Operation finished successfully. The following command can describe the Operation details:
% gcloud services operations describe operations/tmo-acf.118fae92-8cc8-48d4-b0d3-fee58a1afac8
% Service Configuration [2019-01-17r0] uploaded for service [example.endpoints.ea-seed-gcp.cloud.goog]
% To manage your API, go to: https://console.cloud.google.com/endpoints/api/example.endpoints.ea-seed-gcp.cloud.goog/overview?project=ea-seed-gcp
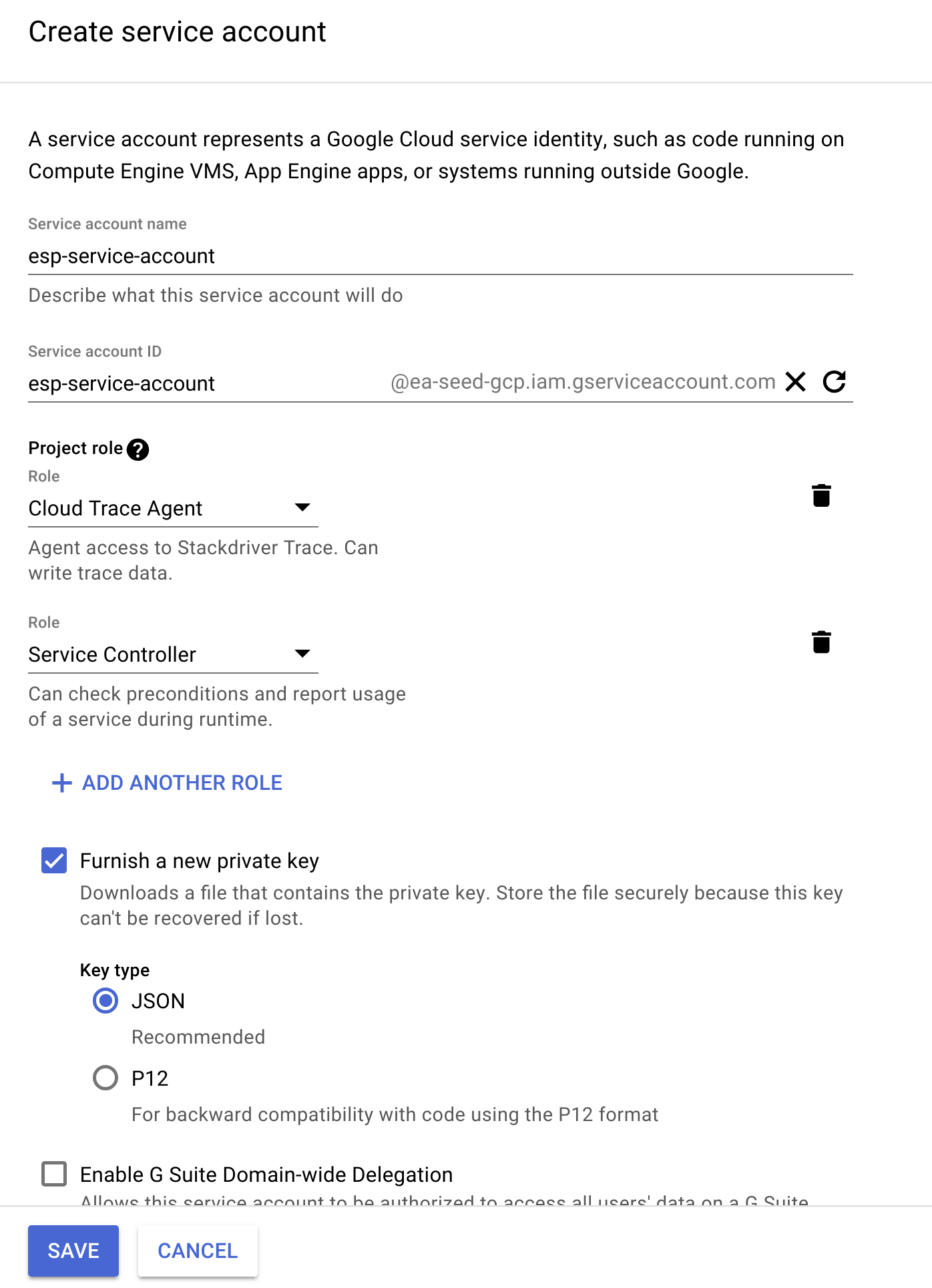
GCP Service Account and Secret
The ESP container needs access to the GCP meta data registry, so a service account needs to exist with access to the following roles:
Service Controller
Cloud Trace Agent
This will produce a .json credentials file that looks something like this:
The following manifest deploys our example gRPC service (example-service) on that listens on port 50095.
gRPC clients can just access the load balancer (via the external IP) on port 80. All traffic (gRPC and JSON/HTTP2) will redirect to the ESP proxy on port 9000
The ESP proxy is a modified nginx server, and will properly route gRPC traffic directly to the backend (i.e. example-service on port 50095), or transcode HTTP/1.1 and JSON/REST into HTTP2 and gRPC before routing into the backend.
Features implemented below:
Keel auto-deploy
Jaeger agent side-car
Load balancer across N-replicas
Public accessible external IP
Google Cloud Endpoints proxy (ESP)
Mount service account secret into volume path for ESP
Kubernetes manifest - example-service.yaml:
apiVersion:apps/v1kind:Deploymentmetadata:name:example-servicelabels:name:"example-service"keel.sh/policy:forcekeel.sh/trigger:pollannotations:# keel.sh/pollSchedule: "@every 10m"spec:selector:matchLabels:app:example-servicereplicas:4template:metadata:labels:app:example-servicespec:volumes:-name:esp-service-account-credssecret:secretName:esp-service-account-credscontainers:-name:example-serviceimage:gcr.io/ea-seed-gcp/example-serviceports:-containerPort:50095-name:espimage:gcr.io/endpoints-release/endpoints-runtime:1args:["--http2_port=9000","--service=example.endpoints.ea-seed-gcp.cloud.goog","--rollout_strategy=managed","--backend=grpc://127.0.0.1:50095","--service_account_key=/etc/nginx/creds/ea-seed-gcp-cb09231df1e9.json"]ports:-containerPort:9000volumeMounts:-mountPath:/etc/nginx/credsname:esp-service-account-credsreadOnly:true-name:jaeger-agentimage:jaegertracing/jaeger-agentports:-containerPort:5775protocol:UDP-containerPort:6831protocol:UDP-containerPort:6832protocol:UDP-containerPort:5778protocol:TCPcommand:-"/go/bin/agent-linux"-"--collector.host-port=infra-jaeger-collector.infra:14267"---apiVersion:v1kind:Servicemetadata:name:example-servicelabels:app:example-servicespec:type:LoadBalancerports:# Port that accepts gRPC and JSON/HTTP2 requests over HTTP.-port:80targetPort:9000protocol:TCPname:http2selector:app:example-service
The manifest can be deployed normally:
$ kubectl apply -f example-service.yaml
deployment.apps "example-service" created
service "example-service" created
If everything deploys correctly, you can confirm the load balancer is running, and it has an external IP (this could take a couple minutes to be created):
$ kubectl get svc example-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
example-service LoadBalancer 172.20.6.70 35.240.13.93 80:30234/TCP 59s
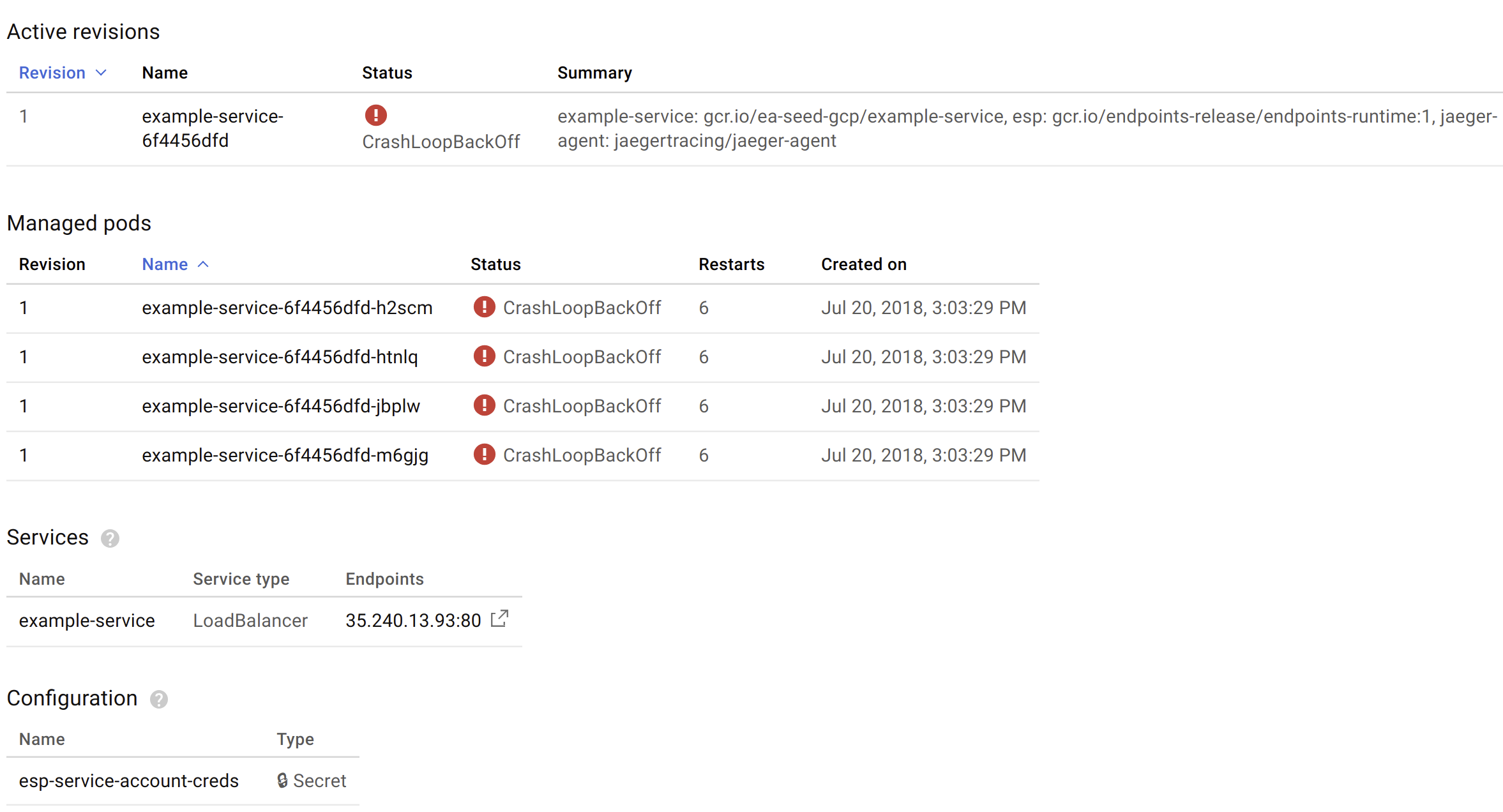
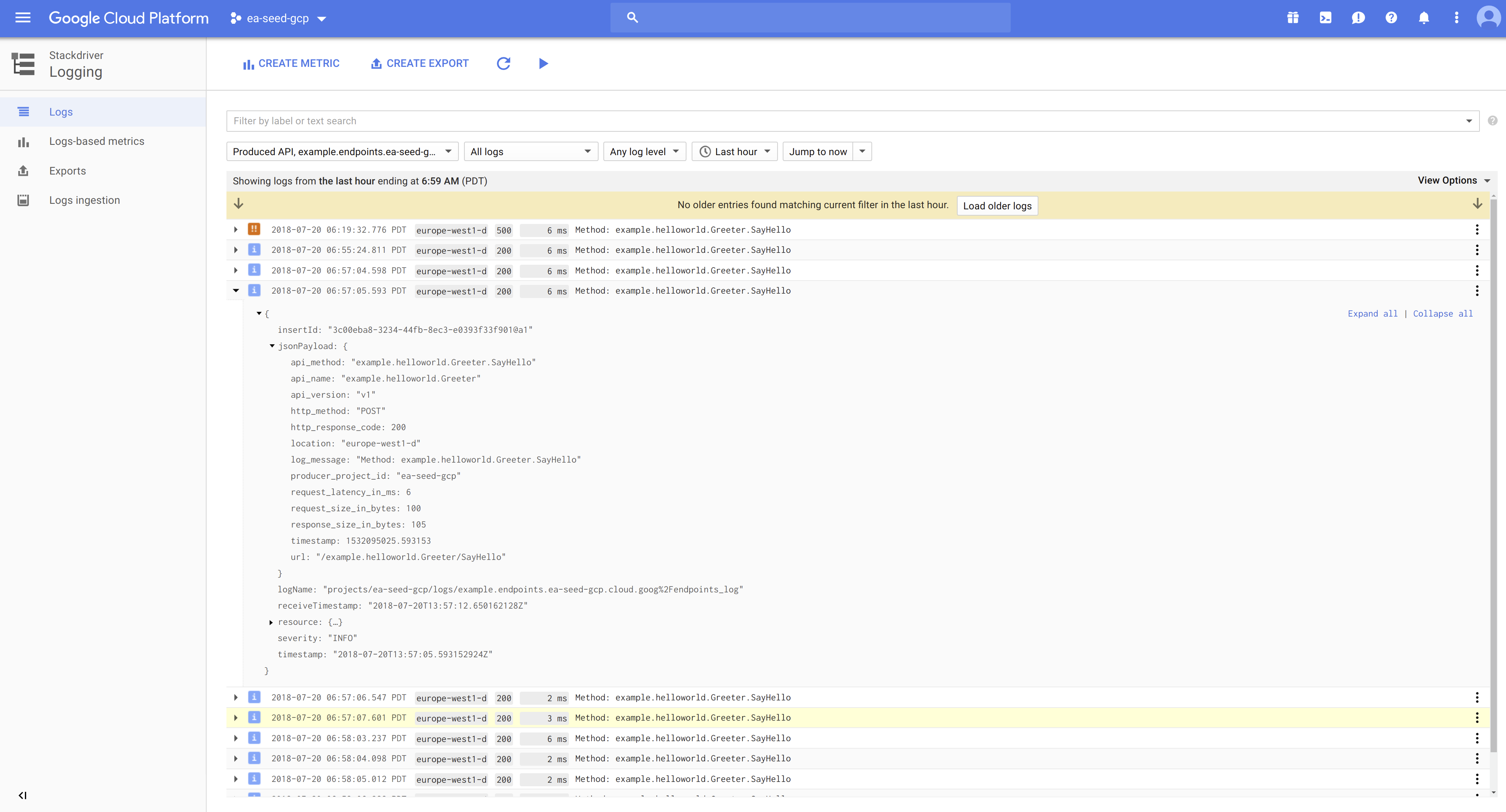
Though, even if the load balancer is up, you also need to confirm that the pods being served by the load balancer are also running successfully:
If you get errors like the above, check the log files to diagnose the reason.
In this example, I clicked on one of the example-service* pods that lists CrashLoopBackOff:
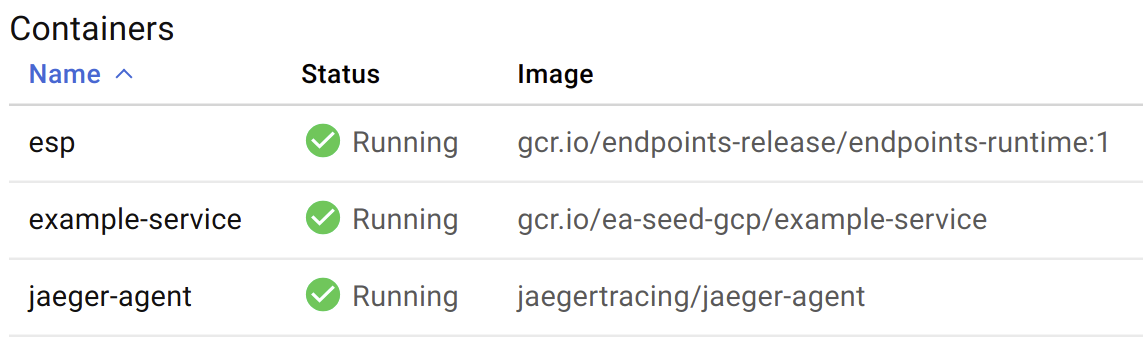
The last container to worry about is the ESP itself. The issue here is our example-service container isn’t deploying correctly. ImagePullBackOff usually signifies that GCP cannot fetch the Docker image from the registry (i.e. gcr.io/ea-seed-gcp/example-service). It looks like I forgot to deploy the example-service image to gcr.io, oops!
After uploading the example-service image, things look much better:
Client Connection
With the Kubernetes deployment (load balancer, ESP proxy, and gRPC service) running correctly, you should be able to connect to the load balancer (i.e. 35.240.13.93 on port 80, in this example) with a gRPC client using the same example.proto schema.
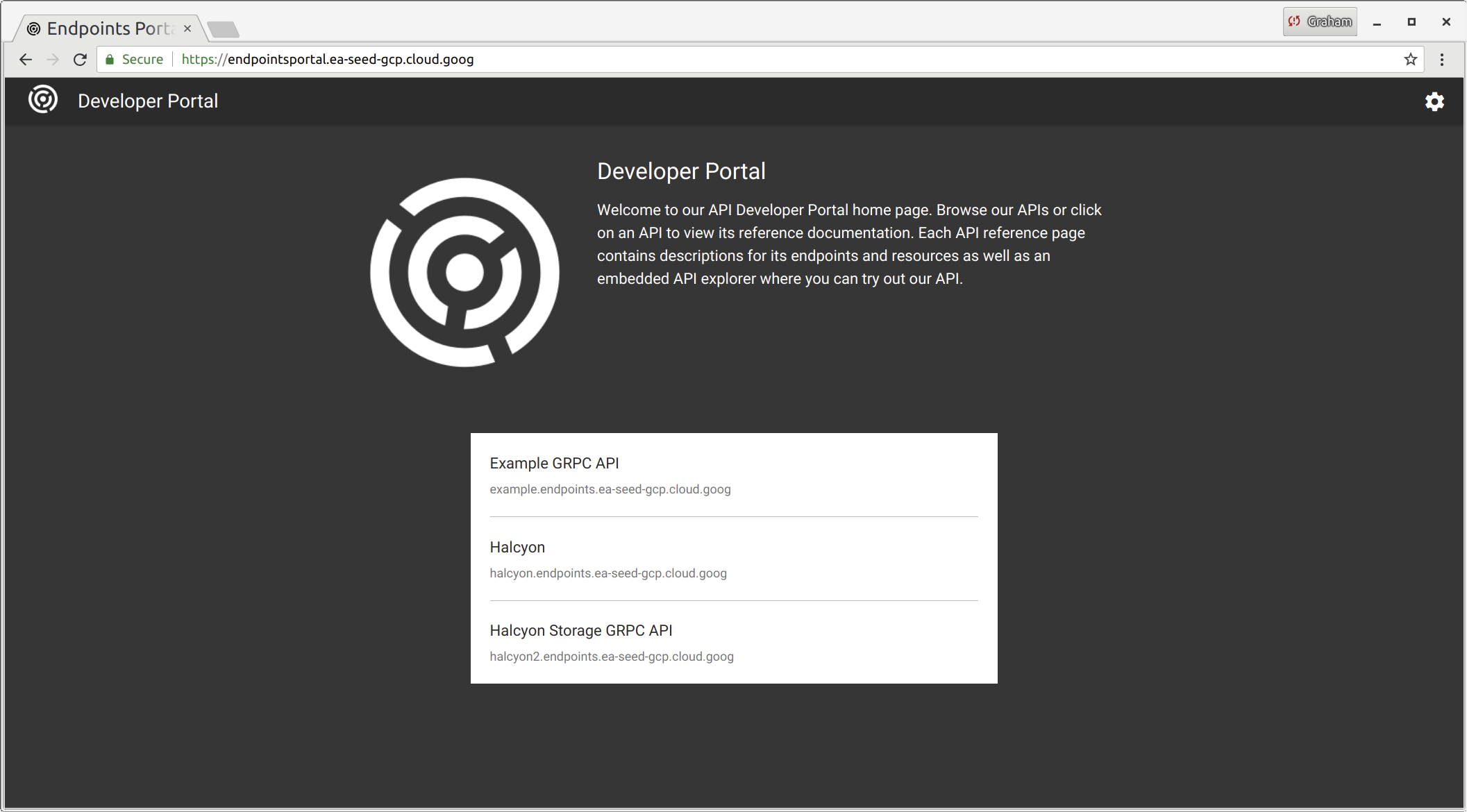
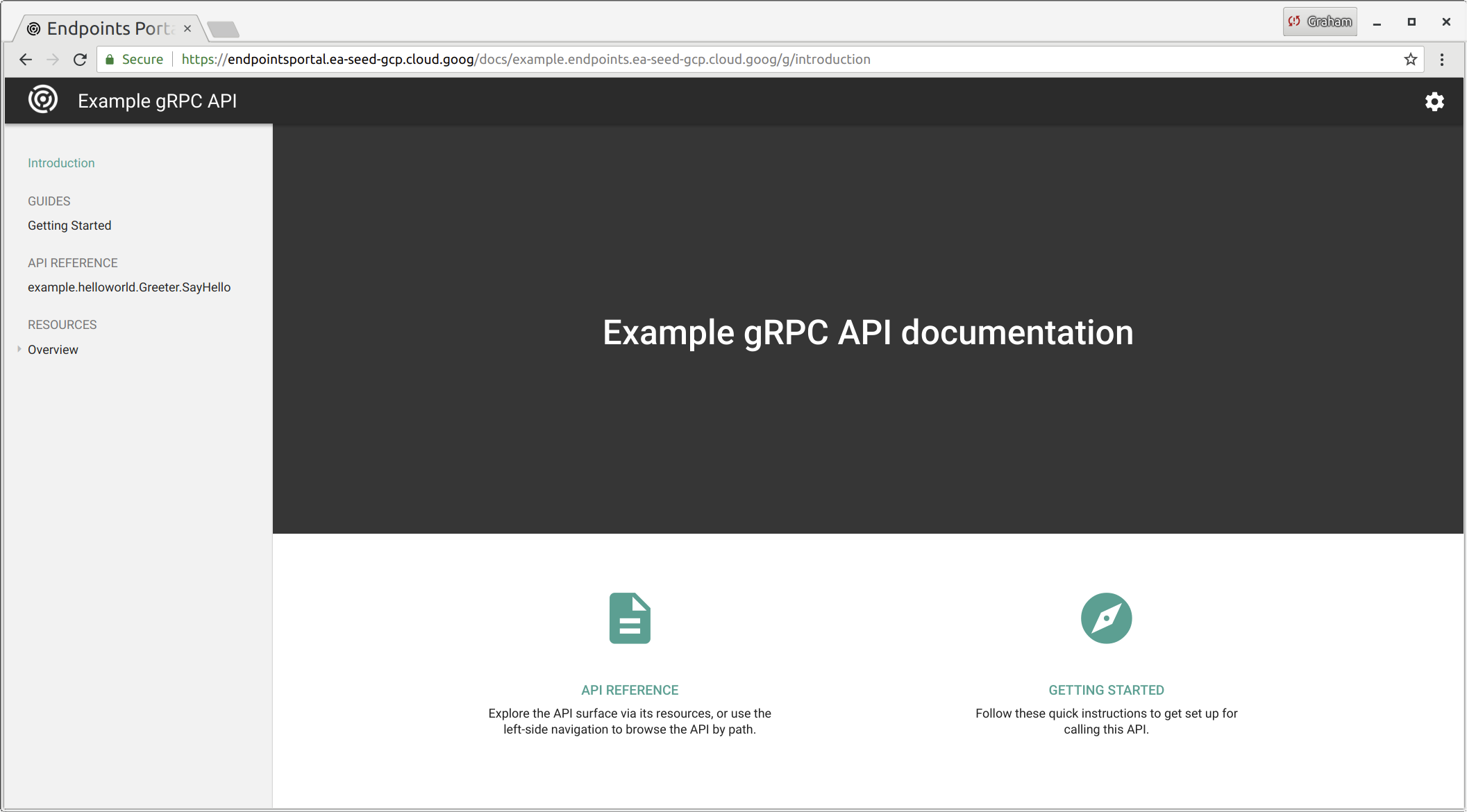
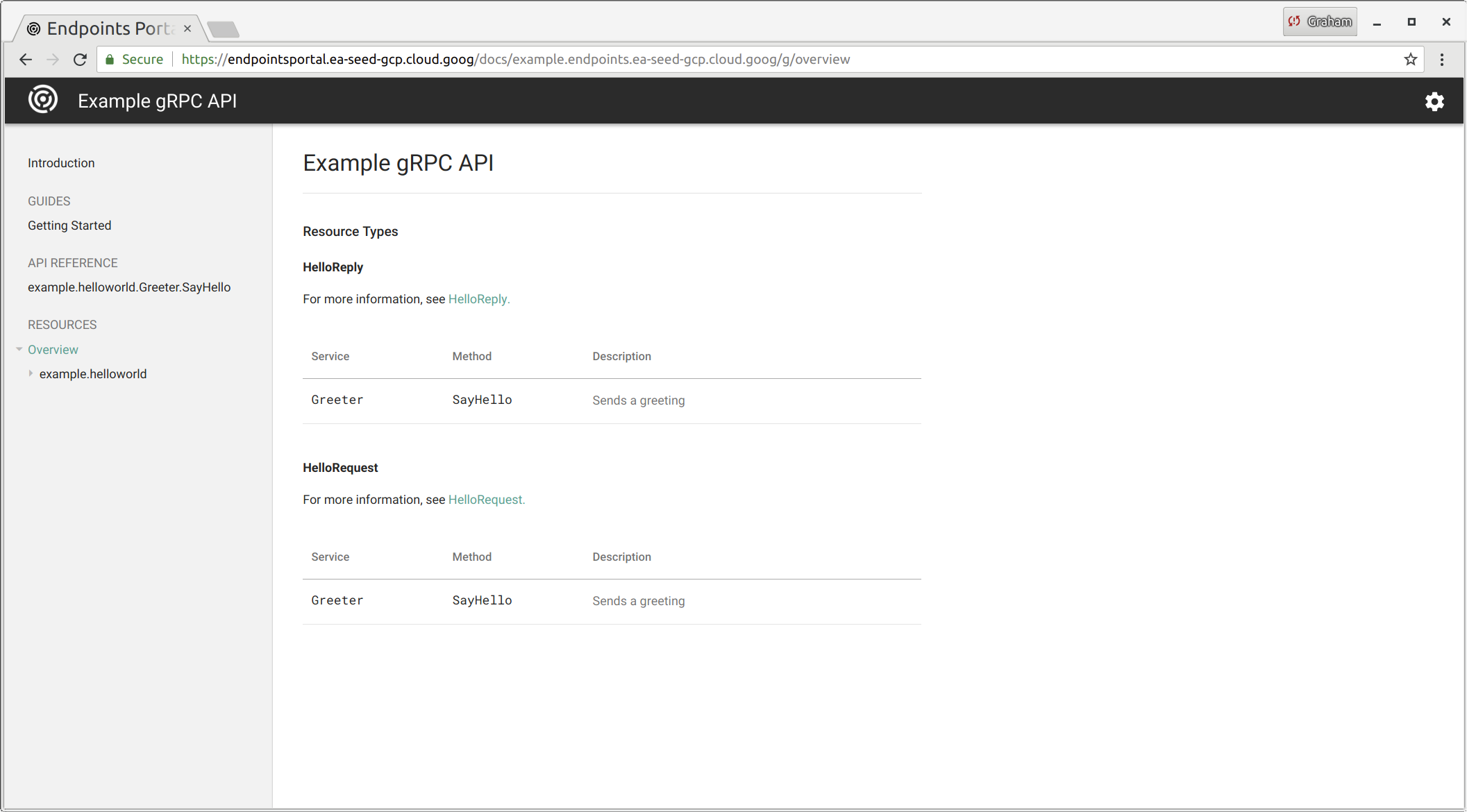
All endpoints get automatically added to a developer portal, along with generated documentation based on the protobuf (which can be given proper descriptions using a variety of annotations). - (i.e. https://endpointsportal.ea-seed-gcp.cloud.goog/)
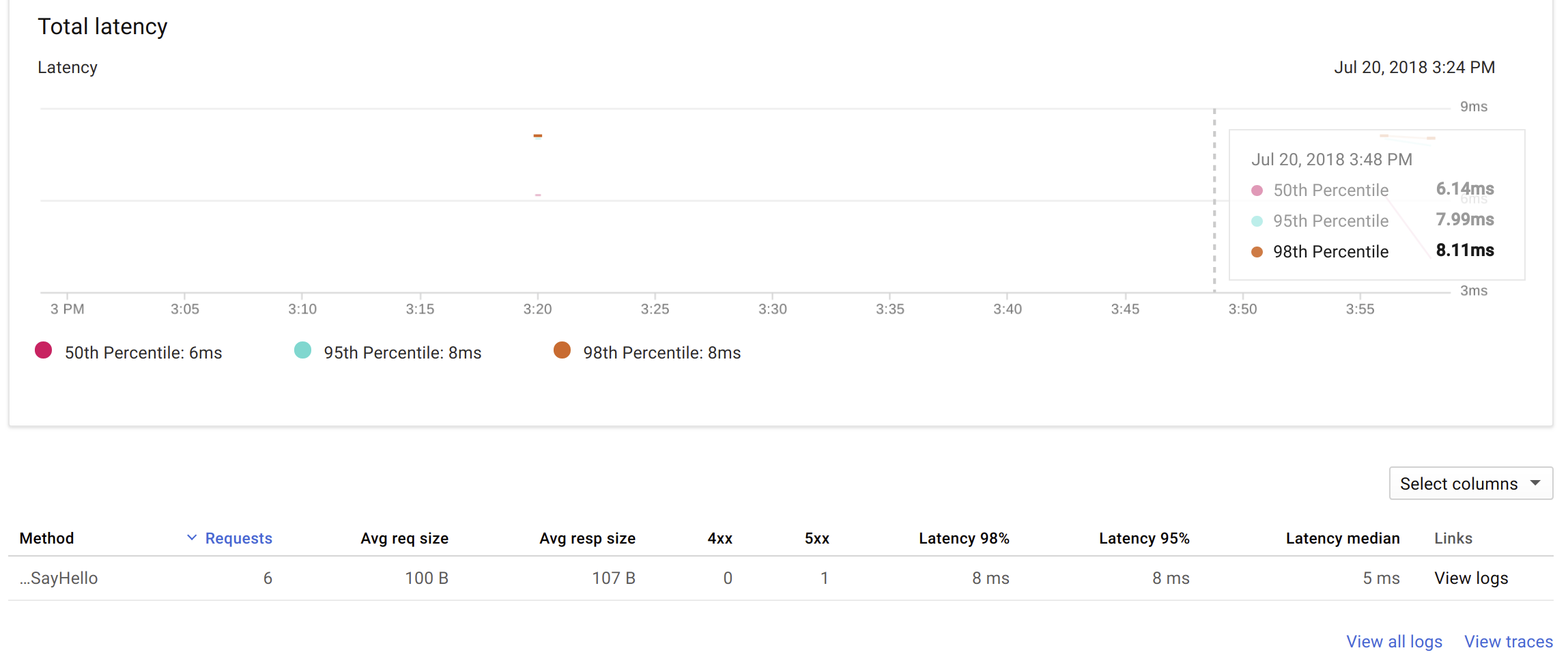
Endpoint StackDriver Logs, Tracing, Monitoring
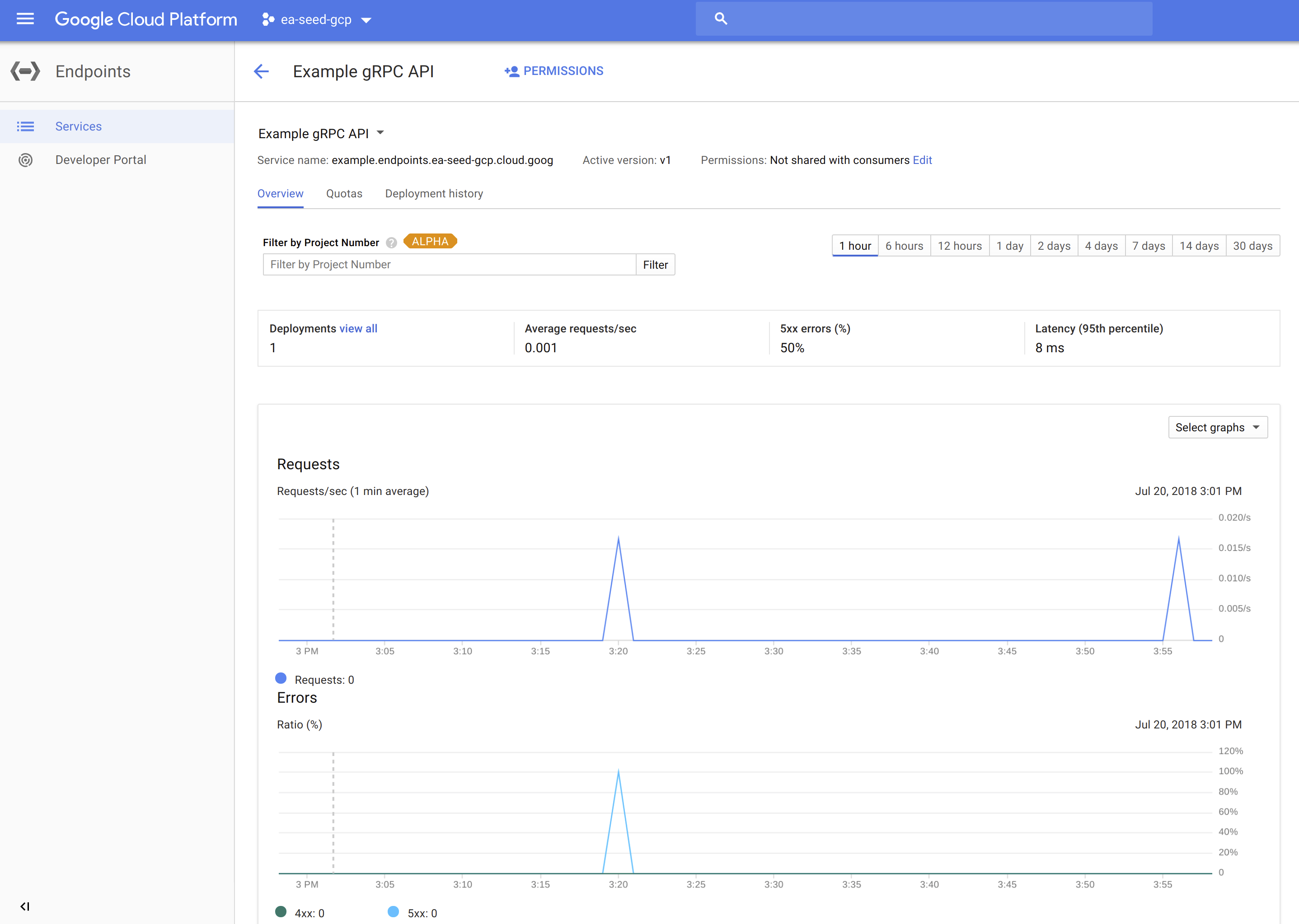
Using Google Cloud Endpoints, we automatically get extensive and rich logs, tracing, monitoring, profiling, etc… with many inter-connected features in the Google ecosystem (especially StackDriver).
Future Improvements
Look into connecting VMs to Google Cloud Endpoints (i.e. NOMAD Windows and macOS servers)
in Pipeline on Docker, Shaders, LinuxLast modified at:
When targetting multiple graphics APIs, a large number of compilers and tools are used. Versioning, deploying and updating all these binaries can be a tedious and complex process, especially when using them with multiple platforms.
In previous posts, I discussed containerizing Microsoft DXC (Linux), Microsoft FXC (Windows under Wine), and signing DXIL post compile (custom tool that loads dxil.dll under Wine).
With the goal of having a shader build service containerized within a Docker container, and scaling it out in a Kubernetes cluster (like GKE), having a single image containing the ability to run all necessary compilers and tools is a critical component.
While developing some crates in rust, I ran into a few crashes in certain situations when using these crates from another application. In order to more easily reproduce the problem, and also minimize or eliminate future regressions, I decided to write some unit tests for these issues, and use them to more easily debug the problems… or so I thought!
Writing the test itself was fairly trivial, and there are plenty of examples and documentation for how rust unit testing is done.
Things took an interesting turn when I ran cargo test (expecting a crash) and my new test wasn’t listed in the output, though the test execution clearly failed.